Ruby app server是如何工作的
但是在深入详细讲解之前,这里先对Ruby app server的概念进行一些介绍
什么是rack
它提供一个介于Webserver与ruby(或ruby框架)之间的一个非常小且又容易使用的接口
可以理解成就是一个ruby package,这个package提供了一个基于Ruby Net::HTTP库开发的easy-to-use interface
![]() Ruby web app通常情况下并不与HTTP的请求和响应直接发生关系,它是通过一个抽象层rack来与HTTP交互,它只需要处理一个抽象过的HTTP请求和响应,web app响应一个请求时会调用一个call方法,接受一个environment的hash参数,同时会响应一个数组,数组里面包括 The status, the headers, and the body.
Ruby web app通常情况下并不与HTTP的请求和响应直接发生关系,它是通过一个抽象层rack来与HTTP交互,它只需要处理一个抽象过的HTTP请求和响应,web app响应一个请求时会调用一个call方法,接受一个environment的hash参数,同时会响应一个数组,数组里面包括 The status, the headers, and the body.
1 2 3 4 5 6 7 8 9 | |
所以rack的作用就是规范两件基本事情,第一是server应该发送什么给ruby app,ruby app应该返回什么给server
可以创建一个很简单的模拟Web Server例子看下,创建一个config.ru文件,再使用命令rackup启动它
1 2 | |
访问http://127.0.0.1:9292 ,就可以看到返回的body
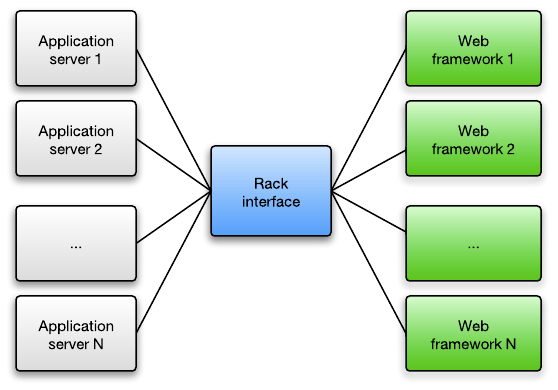
Rack是Ruby的HTTP抽象层。所有的Ruby app server都实现了Rack接口,所以所有的Ruby web framework能够与所有Ruby app server进行无缝工作。 所以app server的职责是接收和分析HTTP请求,然后在底层与web app通过Rack抽象协议进行对话,接着把Rack的响应(也就是application的返回值)转换回真正的HTTP响应。
Rails on Rack
在本地开发时,使用rails server来启动服务时会创建 Rack::Server 对象并启动服务器,创建 Rack::Server 实例的方法如下:传送门 https://github.com/rails/rails/blob/83776676e54b387fc52081ff31cfd7710bae9e03/railties/lib/rails/commands/server/server_command.rb#L150
1 2 3 4 5 | |
Rails::Server 继承自 Rack::Server,使用下面的方式调用 Rack::Server#start 方法:
1 2 3 4 5 6 | |
我们知道在rails项目的根目录有一个config.ru文件,内容如下
1 2 3 4 | |
所以我们其实可以使用rackup命令来代替rails server
多进程阻塞I/O:Unicorn
- unicorn是一个Rack应用的http server
- 具有低延迟、高带宽连接、利用Unix/Unix-like 内核特性的一个多进程服务
- Unicorn 会获取和重启因应用程序出错导致死亡的任务,不需要自己管理多个进程和端口。Unicorn 可以产生和管理任何数量的任务进程。
- 不需要关心应用程序是否是线程安全的,workers 运行在特们自己独立的地址空间,且一次只为一个客户端服务。
- unicorn是热启动,nginx 式的二进制升级,不丢失连接。你可以升级 Unicorn、你的整个应用程序、库、甚至 Ruby 编辑器而不丢失客户端连接。
- unicron是多进程阻塞I/O,每一个进程一次处理一个client。并发的实现是通过构造多个进程,
如果对方没有数据发送,那么read操作就会被阻塞,如果对方接收数据太慢,那么write操作也会被阻塞。由于这种阻塞行为,一个application一次只能处理一个client。那么我们如何一次处理多个client呢?那就构造多个进程.
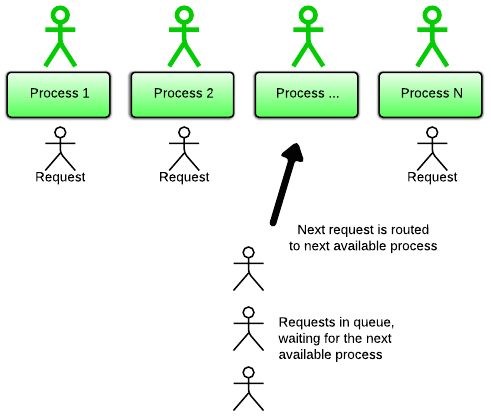
缺点: - 进程本身很重,开销大,所以如果你需要许多I/O并发(例如处理WebSocket,或者你的app需要做很多HTTP的API调用),那么用这种模型并不是太合适。假设我们生产环境有8个worker,每个worker占用内存250M,那么8个worker差不多需要2G的内存,消耗比较大。
- unicorn多进程阻塞I/O模型,那么app server必须要通过使用“反向代理缓存(buffering reverse proxy)”进行保护,反向代理缓存可以处理更多数量的I/O并发。反向代理缓存的请求和响应是用以避免app server拒绝(against)slow client,这些个slow client会对application的其他方面进行阻塞,而反向代理缓存可以高效的将slow client进行纪录。
多线程阻塞I/O: puma
- puma是一个简洁、快速、多线程、高并发HTTP 1.1server专门为Ruby web applications打造的一个web server
- 它可以用于任何支持Rack的application,可以用在开发环境和生产环境
- 每一个进程有多个线程。每一个线程一次处理一个client。并发的实现通过构造小数量的进程,每一个进程包含有多个线程。
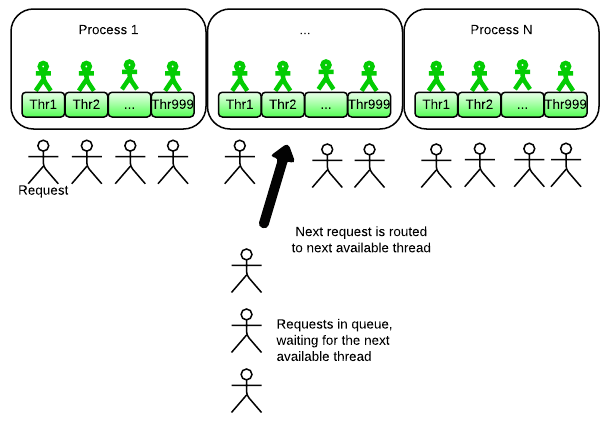
一个进程有多个线程,每一个线程一次处理一个client。因为线程是轻量级的,所以你可以用更少的内存处理相同数量的I/O并发,puma比unicorn最大的好处就是节省内存
缺点:
- 你的application所有代码或程序库必须都得是线程安全的。
- app server应该被反向代理缓存进行保护,原因和多进程I/O阻塞模型一样。相比较而言,多线程的app server不太容易受slow client影响,然而多线程的app server并没有完全解决slow client问题。
slow Client
什么是“slow client”以及为什么这会成为一个问题?slow client可能是mobile client。mobile网络的高延迟非常的恶心。网络阻塞会让正常的client变成slow。一些client变成slow目的就是要攻击你的server,打个比方,把你的application想象成一个市政府,把app server想象成市政府里的办公桌。人们走近一张办公桌(发送一个请求),处理一些文件类的工作(在app内部进行处理),随后人们带着盖有印章的文件离开(收到一个响应)。slow client就像是人们走近一张办公桌,但是一直不离开,这个时候工作人员就无法帮助其他人。
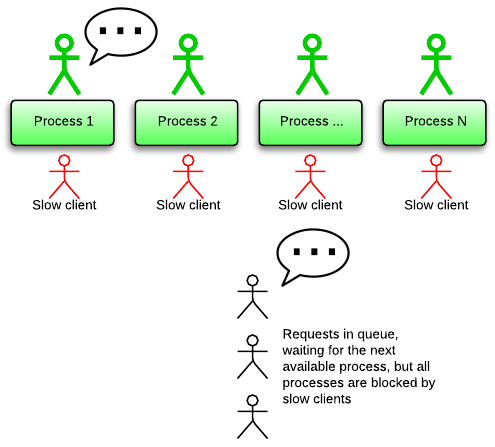
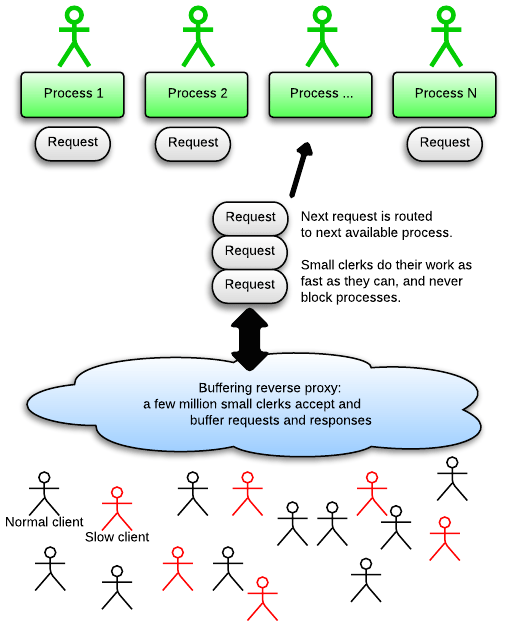
slow Client可以通过使用反向代理缓存解决,反向代理缓存可以处理更大量的I/O并发。想象一下我们把百万的工作人员放到市政府外面。这些工作人员并没有受过处理文件的训练。于此相反,他们只是接收你的文件(缓存你的请求),把这些文件带到市政府内部,然后把带有印章的文件再返还给你(缓存你的响应)。这些外部的工作人员永远不会一直站在办公桌前面,所以他们永远不会引起slow client问题。因为这些外部工作人员只是受到过简单的训练,所以他们的雇佣费用很低(RAM占用低),我们可以雇佣很多。
反向代理通常来说就是Nginx,Nginx缓存了所有的东西,并且可以处理一个被虚拟化了的无限数量的client,像Puma这种多线程server不是很容易受到影响,这是因为它们在市政府内部有更多的办公桌,但是这些办公桌在数量上仍然是有限的,因为比起市政府外面雇佣费用很低的工作人员来说,内部的工作人员需要更多的训练(占用更多的RAM)。
题外阅读
Raptor
Raptor是一款全新的app server,自称性能好的无人能比 http://www.akitaonrails.com/2014/10/19/the-new-kid-on-the-block-for-ruby-servers-raptor#.VEdVfvmSxb8
参考资料
http://blog.gauravchande.com/what-is-rack-in-ruby-rails
http://ohcoder.com/blog/2014/11/11/raptor-part-1/
https://blog.engineyard.com/2015/understanding-rack-apps-and-middleware
http://guides.ruby-china.org/rails_on_rack.html#resources
http://baike.baidu.com/view/1298606.htm
http://zh.wikipedia.org/zh-cn/%E7%BA%BF%E7%A8%8B%E5%AE%89%E5%85%A8